DINO - Emerging Properties in Self-Supervised Vision Transformers
FAIR(Facebook AI Research)에서 ICCV`21에 게재한 DINO - Emerging Properties in Self-Supervised Vision Transformers 를 읽고 작성한 논문 리뷰입니다. 
\[ \newcommand{\black}[1]{\color{black}{#1}} \newcommand{\red}[1]{\color{red}{#1}} \]
Beginning Review
Facebook(현 Meta)에서 발표한 Transformer 기반 Self-supervised learning 논문입니다.
2019년(CVPR`20) MoCo와 2020년(ICLR`20) SimCLR가 Self-supervised learning 분야에 굵직한 임팩트를 주고 나서, 2021년에 트랜스포머 기반의 새로운 Self-supervised learning method가 이 논문을 통해 공개되었습니다. > 저자들은 CNN의 Self-supervised learning과 비교해서 Transformer의 Self-supervised learning이 어떤 새로운 특성을 발견해내고 어떤 성능을 보여줄지 궁금해했다.
Figure.1 : Attention Map of Transformer via DINO
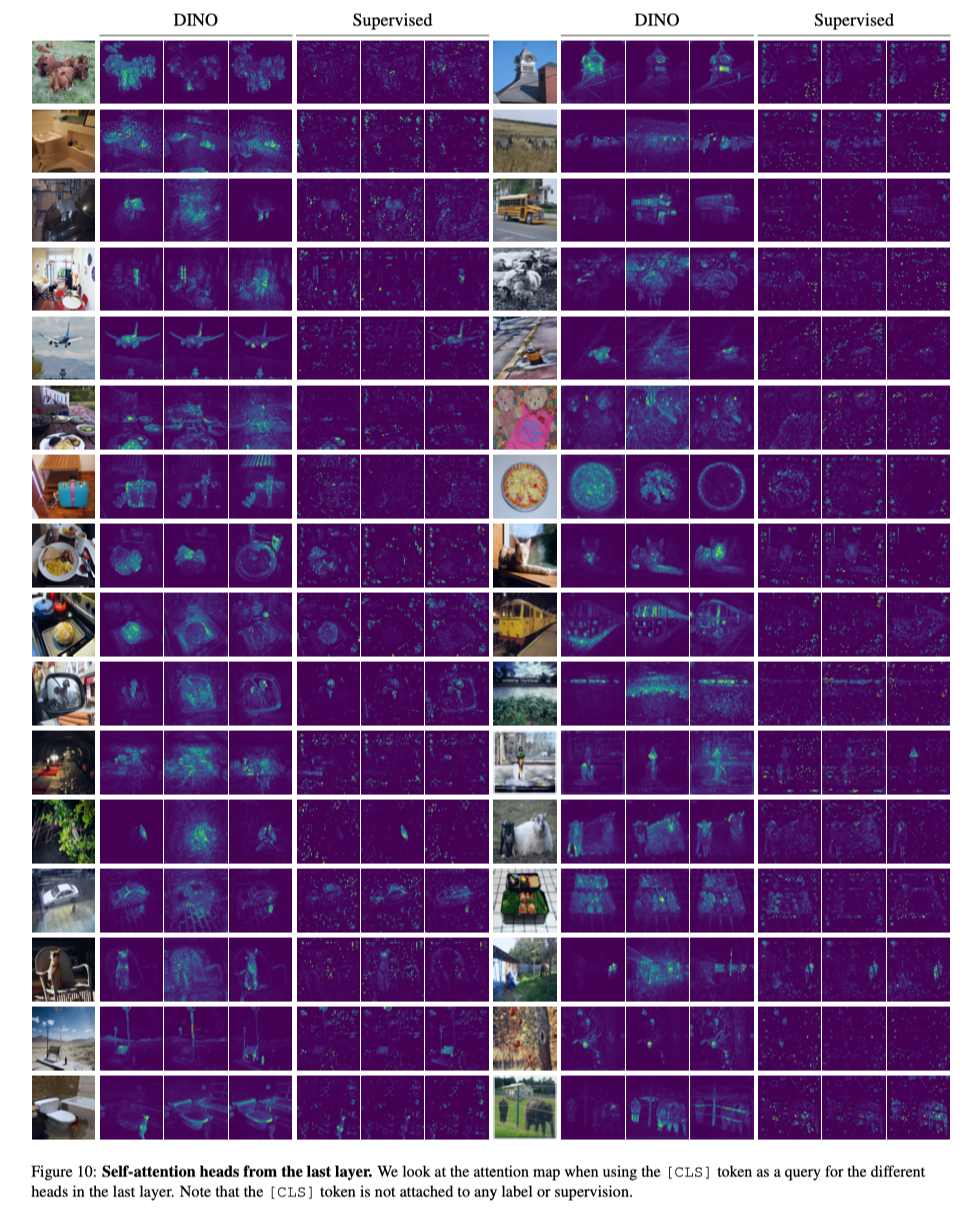
논문을 열어보면 Abstract를 들어가기도 전에 figure.1에 Self-attention map이 등장한다. 저자들은 지도 없이(no-supervision) DINO를 훈련시켰을 때 Vision Transformer(ViT)에서 추출할 수 있는 Self-attention map이라고 이 figure를 소개한다.
마치 열화상 카메라로 물체를 촬영한 듯이 정말 디테일한 부분까지 모델이 Attention map에 잘 표현했다고 할 수 있다. Computer Vision의 분야 중 Weakly Supervised Sementic Segmentation(WSSS)라는 분야에서 다루는 Class Activation Map(CAM)과 비슷한 ’시각화 맵(Visualization Map)’이라고 할 수 있는데, 정성적인 결과가 매우 뛰어나다고 할 수 있다.
참고 : Figure 1은 ViT의
[CLS]토큰의 벡터를[batch, embed_dim]마지막 Layer의 모든 Head에서의 Attention weight를 시각화 한 것입니다. (CLS 토큰이 Query이고 패치 토큰이 Key)*
 DINO의 정성적인(Qualitative) 결과(Figure 1)는 매우 뛰어나다. 객체의 디테일한 부분을 놓치지 않고 잡아내며 Computer Vision 분야에서의 Transformer의 위용을 다시 한번 보여줬다. 심지어 모델은 정답을 배우지 않은 no-supervision 훈련의 결과물이다.
DINO의 정성적인(Qualitative) 결과(Figure 1)는 매우 뛰어나다. 객체의 디테일한 부분을 놓치지 않고 잡아내며 Computer Vision 분야에서의 Transformer의 위용을 다시 한번 보여줬다. 심지어 모델은 정답을 배우지 않은 no-supervision 훈련의 결과물이다.
그래서 정확히 얼마나 뛰어난데?
논문의 Approach및 Analysis에 앞서 DINO가 정성적인 결과 말고도 정량적인 측면에서 얼마나 뛰어난지에 대해 미리 살펴보고 리뷰를 이어 나갈것이다.
1. Main Results (ImageNet Classification)

이 Table은 DINO 논문의 가장 핵심적인 성능 평가 Table입니다. Self-Supervised Learning에서는 보통 Foundation Model(Down-stream task를 수행하는 사전훈련된 모델)을 만드는것에 주안점을 둔다.
그리고 SSL로 학습시킨 모델의 Pretrained weight를 사용해서 MLP로 구성된 Linear Classifier 또는 kNN 또는 Logistic Regression을 분류목적으로 모델 마지막 단에 달아주고 Downstream Task를 및 훈련-평가하는 과정을 거친다.
그래서 SSL 연구가 모델의 지능으로 Input data를 ‘알아서(self)’ 어디까지 해석 할 수 있는지 그 끝을 보기 위한 연구로 해석된다.
DINO는 이전에 발표된 Work들과 비교해서 상대적으로 더 뛰어난 성능을 보인다.
Table에서 재밌는 점은 DINO의 Main inspiration은 Do Transformer SSL well?인데 성능 평가에서는 RN50(ResNet50)을 Backbone으로 사용했을때도 다른 이전 Work들 보다 뛰어난 성능을 보였다는 것이다.
그 말은 단순히 Transformer를 SSL에 적용시켜 보았다는 Contribution뿐만 아니라 그 외의 SSL에 관한 Contribution이 존재한다는 말이다.
또 한가지 DINO의 눈에 띄는 장점으로는 학습이 필요없이 알고리즘으로 Clustering만 필요로 하는 kNN 방식의 Classifier만으로도 이전 Work에 비해 훌륭한 성능을 냈다는 점이다.
논문의 Appendix. A.에서도 DINO는 시간과 자원이 상대적으로 더 필요한 Linear Classifier보다 가볍고 빠른 kNN 알고리즘에 유연성(flexibility)을 가진다고 설명한다.  본문 : “DINO might offer more model flexibility that benefits the k-NN evaluation. K-NN classifiers have the great advantage of being fast and light to deploy, without requiring any domain adaptation. Overall, ViT trained with DINO provides features that combine particularly well with k-NN classifiers.
본문 : “DINO might offer more model flexibility that benefits the k-NN evaluation. K-NN classifiers have the great advantage of being fast and light to deploy, without requiring any domain adaptation. Overall, ViT trained with DINO provides features that combine particularly well with k-NN classifiers.
추가로 Table에는 훈련속도와 관련된 지표(im/s : 초당 처리하는 단일 이미지의 장수)도 주어지고 전체 Parameter 개수(Million 단위)도 주어져 있기 때문에 DINO의 성과를 여러 방향으로 평가할 수 있다.
성능 Table을 보고 설명할 수 있는 Dino의 특징을 정리하자면 다음과 같다.
- SSL 해보니까 Backbone 쓸 때 ResNet 쓰는거보다 ViT의 성능이 뛰어나더라.
- Dino 방식으로 SSL을 하면 ResNet도 성능이 좋아지더라.
- ViT의 Parameter중에서 Patch size가 작을 수록 성능이 좋다.
- 당연한 얘기지만 ViT의 전체적인 모델 규모가 크면 클수록 성능이 좋다.(B>S>T)
- 성능이 좋을수록 im/s는 예외없이 구려진다. (DINO 자체는
V100*8개*2개서버의 자원을 활용해3days간 Training. ImageNet1k)
 SSL에서도 VisionTransformer는 역시 PatchSize Parameter가 중요하다.
SSL에서도 VisionTransformer는 역시 PatchSize Parameter가 중요하다.
 DINO의 방식대로 SSL을 한다면 CNN based또한 이전 Work들의 성능보다 높다.
DINO의 방식대로 SSL을 한다면 CNN based또한 이전 Work들의 성능보다 높다.
2. Transfer learning (vs. Supervised)
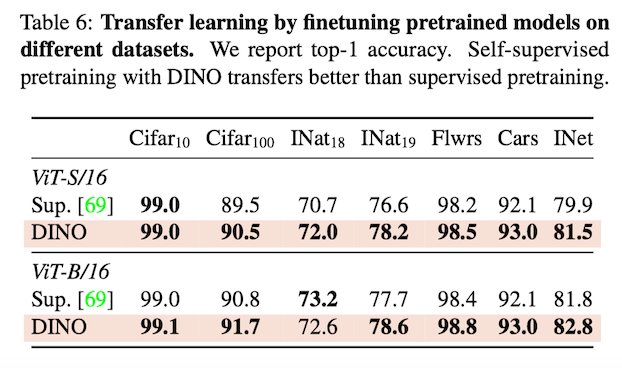 지도학습 된 모델과의 전이 학습 성능을 평가한 Table
지도학습 된 모델과의 전이 학습 성능을 평가한 Table
DINO는 Unsupervised Training으로 Supervised Training을 앞지른다. 그만큼 모델이 개별 이미지의 특징이 되는 부분을 잘 이해하고 있다는 뜻이다. (e.g. Texture, Tactile과 같은 Properties)
3. etc
Copy detection, Image Retrieval, Video object segmentation에 관한 성능평가도 존재하지만 이 리뷰에서는 다루지 않는다.
Approach
DINO의 우수한 성능을 봤으니 논문에 쓰인 내용을 바탕으로 이제 어떤 Flow로 모델이 훈련되는지 알아보겠다. 그리고 실제 코드를 뜯어보고 그 안에 숨은 디테일도 분석해 보겠다. ## 1. Self-training and knowledge distillation.
Model Flow
 DINO 훈련 진행 흐름
DINO 훈련 진행 흐름
Teacher와 Student로 구성되어 우수한 Teacher 모델의 지식(Knowledge)을 증류(Distillation)하는 기법인 KD(Knowledge Distillation) 방법에 대해서 알고 있다면 이해가 쉽습니다.
DINO는 Self-supervised learning에 KD를 적용했다. (이 Self-supervised 훈련 방식은 DINO가 처음 제안한 방식은 아니다.)
Algorithms

 Algorithm of DINO Multi-Crop Strategy를 사용하지 않았을 때의 수도코드와 실제 코드 비교. (실제 코드는 Multi-Crop Strategy를 사용한 경우.)
Algorithm of DINO Multi-Crop Strategy를 사용하지 않았을 때의 수도코드와 실제 코드 비교. (실제 코드는 Multi-Crop Strategy를 사용한 경우.)
 실제코드에서의
실제코드에서의 DINOLoss 클래스
2. Image Transformation and Multi-Crop Strategy.
Image Transformation은 Multi-Crop Stategy를 사용하는지 안하는지에 따라 달라진다.
Model Flow Figure에서는 설명을 위해 Multi-Crop Stategy를 사용하지 않는 Global View만 다뤘다.
Multi-Crop의 종류로는 global view와 local view가 있는데, torchvision.transforms.RandomResizedCrop 모듈을 사용한다.
global view와 local view의 차이점은 scale이 global(전역적)인지 local(지역적)인지에 대한 내용이다.
global view image는 사진에서 넓은 spatial을 포함하게 되고 \(224^2\) 의 사이즈를 갖는다.
local view image는 사진에서 좁은 spatial을 포함하게 되고 \(96^2\) 의 사이즈를 갖는다.
결국 Dataloader에서 불러올 때 images의 shape은 [10,B,3,h,w] 이며 10가지 view의 이미지 세트가 배치 개수만큼 들어있고 이 중 [:2]에 해당하는 global view는 Teacher Network에만 들어가고 Student는 전부를 입력받는다.
Multi-Crop Stategy가 적용 된 뒤에 모델에 전달되는 코드는 다음과 같다.
with torch.cuda.amp.autocast(fp16_scaler is not None):
teacher_output = teacher(images[:2]) # only the 2 global views pass through the teacher
student_output = student(images)
loss = dino_loss(student_output, teacher_output, epoch) 이해를 돕기 위한 Dataset Input Overview
이해를 돕기 위한 Dataset Input Overview

 augmentation 부분 Class
augmentation 부분 Class

 Left : MultiCropWrapper Class, Right : student, teacher 선언 하는 부분
Left : MultiCropWrapper Class, Right : student, teacher 선언 하는 부분
\[ \black{\min_{\theta_s}{\sum_{x \in \{ x^g_1 , x^g_2 \}}}{\sum_{x^{\prime} \in V , x^{\prime}\neq x}} H(P_t{(x)}, P_s{(x^\prime)})} \]
\(x^g\) : Global view of \(x\) (only \(2\))
\(x^{\prime}\) : Local view of \(x\) (user setting; default : \(8\))
\(V\) : Local view set of \(x\)
Teacher network의 Input과 Student network의 Input은 같은 이미지지만 Resolution이 다른 Augmentated Image가 들어간다. 이는 “local-to-global” 개념과 일맥상통하게 한다.
student는 local을 학습하고 가중치를 teacher에게 전달함. student는 global view를 학습하는 teacher와 닮아가게 됨
class DataAugmentationDINO(object):
def __init__(self, global_crops_scale, local_crops_scale, local_crops_number):
flip_and_color_jitter = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply(
[transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.2, hue=0.1)],
p=0.8
),
transforms.RandomGrayscale(p=0.2),
])
normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
# first global crop
self.global_transfo1 = transforms.Compose([
transforms.RandomResizedCrop(224, scale=global_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(1.0),
normalize,
])
# second global crop
self.global_transfo2 = transforms.Compose([
transforms.RandomResizedCrop(224, scale=global_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(0.1),
utils.Solarization(0.2),
normalize,
])
# transformation for the local small crops
self.local_crops_number = local_crops_number
self.local_transfo = transforms.Compose([
transforms.RandomResizedCrop(96, scale=local_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(p=0.5),
normalize,
])3. Stop gradient and EMA update(student->teacher)
DINO 모델의 특징으로는 Teacher 모델은 직접 Back Propagation을 통해 파라미터들을 업데이트 하지 않고 Student Parameter에서 Exponential Moving Average(EMA : 지수이동평균) 방식을 사용해 Parameter를 업데이트 한다는 것이다. (MoCo에서 Momentum Update를 하는 방식과 동일하다.)
\[ \black{\theta_{t} = {\lambda}{\theta}_t + ({1-\lambda})\theta_s} \]
 best acc에서 Momentum Update 경향성, Cosine Scheduler를 따른다. (copyrights: seilk)
best acc에서 Momentum Update 경향성, Cosine Scheduler를 따른다. (copyrights: seilk)
EMA에 대한 업데이트 규칙은 위의 식과 같으며 \(λ\)는 훈련 중 0.996에서 1까지의 Cosine Scheduler를 따른다.
# EMA update for the teacher
with torch.no_grad(): # Stop gradient
m = momentum_schedule[it] # momentum parameter
for param_q, param_k in zip(student.module.parameters(), teacher_without_ddp.parameters()):
param_k.data.mul_(m).add_((1 - m) * param_q.detach().data)이렇게 하는 이유는 특별한 인과관계가 있다기 보단 귀납적으로 이 프레임워크에서 이 방법이 특히 잘 작동한다는 것을 발견했기 때문이라고 설명한다.
Teacher model이 EMA 방식으로 student의 parameter를 받아오기 때문에 이는 student의 시간의 변화에 따른 checkpoint를 부드럽게 ensemble을 하여 student model의 일반성을 체득할 수 있다고 설명한다.


위의 Figure는 DINO에서 EMA 방식으로 했을 때 Pretrained 되지 않은 Teacher가 Student의 성능보다 우수하므로 의미론적으로도 Teacher network를 Teacher network라고 취급 할 수 있음을 보여줍니다.
teacher network의 파라미터는 dynamically하게 student의 파라미터의 평균이 되는데 이는 Polyak-Ruppert averaging과 같은 모델 ensemble 효과를 보인다.momentum update를 여러 학습 간격을 두고 ablation 했을때의 Top-1 acc
위의 Figure에 모델의 Top-1 Accuracy를 측정한 자료가 나와있다. 단순 모델 복제(Student Copy), 직전의 이터레이션 모델 복제(Previous iter), 직전의 에폭 모델 복제(Previous epoch), 모멘텀 업데이트(Momentum)의 성능이 비교대상군이다.
Self-supervised Learning에서 가장 두려운 상황이 Model Collapse 상황이다.
Model Collapse 상황이란 간단히 말하자면 입력값과 상관없이 출력값이 하나의 차원으로 dominate 되거나, 모든 차원에 대하여 uniform 한 상황을 말한다.
SG(Stop gradient)를 걸어놓고 가중치를 업데이트하는 상황에서 Teacher의 가중치가 매우 빠르게 업데이트 되면 Teacher와 Student의 앙상블 효과를 기대할 수 없게 되고 두 모델의 차이점이 없어지게 되면 자연스레 Model Collapse 문제가 일어나게 된다.
SSL에서의 “collapse” 개념은 학습된 표현이 다양성이나 구별력을 상실하여 유사하거나 구분할 수 없게 되는 현상을 일컫는다. SSL 학습 중에 모델이 collapse되면, 모델이 데이터의 내재된 구조나 변동성을 제대로 포착하지 못하고 입력에 상관없이 유사한 표현을 생성하게 된다. 이러한 이유 때문에 collapse는 모델이 사용하는 간단하거나 비효율적인 학습 전략으로 인해 발생할 수 있다. Collapse는 다양한 형태로 나타날 수 있으며, 예를 들면 다음과 같다: 1. Mode collapse: 모델이 주어진 데이터의 다양성을 무시하고 몇 가지 우세한 Mode나 Pattern으로 collapse되는 경우이다. 이로 인해 표현은 입력 분포의 전체 변동 범위를 포착하지 못하게 된다. 2. Semantic collapse: 모델이 서로 다른 입력을 동일하거나 유사한 표현으로 매핑하여 의미적인 차이를 무시하는 경우이다. 결과적으로 모델은 의미적으로 다른 객체나 개념을 구별할 수 없게 된다. 3. Gradient collapse: 모델의 기울기가 지나치게 작아지거나 사라져서 모델 파라미터에 효과적인 업데이트가 이루어지지 않는 경우에 기울기 collapse가 발생할 수 있다. 이는 모델이 나쁜 지역 최적해에 갇히거나 의미 있는 표현을 학습하지 못하게 할 수 있다.
4. Centering, Sharpening
앞서 말한 Model Collapse를 해결하기 위해서 DINO에서는 Centering과 Sharpening 기법을 사용한다.
이전 Work들의 Avoiding Collapse의 방법으로 Contrastive loss, Clustering constraints, Predictor, Batch Normalization 등이 있는데, DINO에서는 Teacher output의 Centering과 Sharpening을 해주는 것만으로 모델을 안정화(Stablization)할 수 있다고 설명한다.
Centering은 Output이 한개의 차원에 지배적인(dominated) 상황을 억제하지만 Output이 Uniform distribution이 되도록 하는 특성을 가지고 있고, Sharpening은 그러한 Centering의 반대의 특성을 가지고 있습니다.
\[ \black{g_t(x) ← g_t(x) + c} \]
\[ \black{c \leftarrow mc + (1 - m)\frac{1}{B} \sum^{B}\_{i=1}g\_{\theta_t}{(x_i)}} \]
위 수식을 설명하자면 teacher parameter가 student model에 의해 momentum update 가 된 후 추가로 \(c\)를 더해줌으로써 teacher parameter(\(g_{\theta_t}\))는 \(c\)에 의해 보정된다.
이 때 Centering 인자인 \(c\)도 center_momentum에 의해 매 iteration마다 update된다. \(g_{\theta_t}\) 의 배치 단위의 평균도 \(c\) 업데이트에 적용 되면서 \(c\) 또한 점차적으로 momentum updated \(g_{\theta_t}\)의 평균적인 값의 영향을 받는다고 할 수 있다.
이렇게 되면 dynamic 하게 매 상황(momentum update)에 맞는 centering을 적용할 수 있게 된다는 것에 의미가 있다고 생각한다.
 Code 상에서의 Centering
Code 상에서의 Centering
 Target Entropy : Teacher model의 Output의 ’정보 불안정성(unstable)’을 의미한다. 이 값이 높을 수록 Teacher model이 뱉는 Softlabel이 일관되지 않고 중구난방으로 값이 튄다는 것을 의미한다.
Target Entropy : Teacher model의 Output의 ’정보 불안정성(unstable)’을 의미한다. 이 값이 높을 수록 Teacher model이 뱉는 Softlabel이 일관되지 않고 중구난방으로 값이 튄다는 것을 의미한다.
KL divergence : Student Model Output과 Teacher Model Output의 분포 차이도를 의미한다. 이 값이 0에 가까울 수록 Student와 Teacher가 같은 feature를 추출한다고 할 수 있고 이렇게 되면 Model은 더 이상 새로운 Feature를 학습 할 수 없고 해당 결과에 Dominate된다고 간주한다.
위 figure는 Centering 과 Sharpening을 각각 적용하였을 때 and 함께 적용하였을 때에 SSL에서 Collapse가 일어나는 주요요인을 분석한 비교 실험에 관한 figure이다. 자세한 설명은 figure caption에 소개되어 있다.
결론은 둘 다 사용해야 Model Collapse를 방지하는것에 효과적이라는 말
5. Cross-Entropy
\[ \black{P_{s}(x)^{(i)} = \frac{\exp{(g_{\theta_s}{x}^{(i)}} / \tau_{s})}{\sum_{k=1}^{K}{\exp(g_{\theta_s}{(x)^{(k)}}}/{\tau_s})}} \]
\[ \black{\min_{\theta_s}{H(P_t(x), P_s(x))}} \]
\[ \black{H{(a, b)} = −a\log{b}} \]
\(P_t\) : Teacher Network Probability
\(P_s\) : Student Network Probability
\(g_{\theta_t}\) : Teacher Network
\(g_{\theta_s}\) : Student Network
\(\tau\) : Temperature
\(K\) : Dimension of output
DINO는 SSL(self-supervised learning)에 사용되는 샴 네트워크(Siamese-Network)를 지식 증류(Knowledge Distillation)의 한 형태로 구성한다. 여기에서 Student network는 더 나은 성능의 Teacher network의 출력을 모방하도록 훈련된다. 이를 달성하기 위해 DINO는 Teacher network와 Student network의 출력 사이에 Cross-Entropy를 사용하여 Student network를 교육하는 동시에 Teacher network에 Stop gradient를 적용하여 훈련 중에 업데이트되지 않도록 한다.
마치며
대기업 논문이라 그런지 Git 코드 관리도 굉장히 잘 되어 있고 방법론을 여기저기에 쓸 만 할 것으로 생각된다.
이 리뷰에 전부 다 담지 못한(TODO Review) 굉장히 디테일한 Ablation Study가 있는데 그만큼 실험적 증명이 탄탄하고 우연의 일치로 좋은 결과가 나왔다는 반박을 할 수 없도록 하는 논문인 것 같다.
끝으로 시각자료들을 첨부하고 논문리뷰를 마친다.🔜
1. 대략적인 전체 학습 과정

2. Supervised 와의 Self-attention Map 결과물 비교
3. Attention Map of Video

ps. 근데 DINOv2도 나옴