GraphAdapter - Tuning Vision-Language Models With Dual Knowledge Graph
이 글은 Xin Li et al. (University of Science and Technology of China)이 NeurIPS`23에 게재한 GraphAdapter: Tuning Vision-Language Models With Dual Knowledge Graph를 읽고 정리한 글입니다.
Introduction
이 논문은 Graph Theorem, Graph Convolution Network의 지식을 VLM (Vision Lanuguage Model) 에 적용한 논문이다. VLM, MLLM (Multi-modal Large Language Model) 관련 논문들을 많이 읽어 보았는데 (BLIP-2, Flamingo, LLaVA, CoCa, GILL 등), Graph Theorem을 적용한 논문은 처음본다.
그렇다고 억지로 끼워 맞추기 식 논문은 아니고 나름의 문제상황을 잘 정의해서 해결한 논문으로 재밌게 읽을 수 있었다.
Contributions
Contribution을 살펴보기 이전에 논문의 주장하는 Prior work에서의 문제상황은 다음과 같다.
- 그 동안 Adapter 기반의 VLM들은 Single Modality에서의 Adaptation을 수행하므로 Visual feature와 Textual feature를 모두 고려하지 않는다.
- 데이터들 간의 서로 다른 semantics 또는 classes 정보들에 대한 명시적인 관계 정보를 다루는 Prior Work는 없었다.
인데, 솔직히 나로서는 1.에 대해서는 그냥 그런적이 없었을 뿐이지 문제가 되려나? 라고 받아들였고 저 상황이 왜 문제가 되나? 에 대한 의문점이 아직 남아있다.
2.는 저자들이 노골적으로 Graph Learning로 풀 수 있는 가장 전형적인 Case를 설명하고 있는데, 이 문제는 해결하게 된다면 VLM 측면에서도 도움이 될 것 이라는 생각을 하고 읽었다.
2.에 대한 부연설명: 나는 “각 Class의 관계 정보를 다룬다.” 라고 했을때 Self-supervised Learning에서 대표적으로 사용되는 Contrastive Learning이 떠올랐다.
Contrastive Learning은 High-level에서 본다면 해당 Class와 그 Class의 Negative Sample들 과의 관계성을 모델에게 학습시키는 과정이라고 설명할 수 있다. 이 논문에서는 Contrastive Learning을 쓰진 않았지만 Graph Learning 에서 각 Node를 Class로 보며 GCN으로 Class간의 관계(Edge)를 모델링 하는 것을 생각하면 Class간의 관계를 implicit하게 모델이 이해하고 특정 Class를 Discriminate 하는데 도움이 될 것이라고 생각했다.따라서 이 문제는 해결하면 VLM의 입장에서 나쁠건 없다고 생각했다.
그래서 위 문제 상황에 대한 저자들이 주장하는 Contributions은 다음과 같다.
- Dual-modality(text and vision) structure knowledge with Dual knowledge graph
- It leverage the fused visual and language knowledge for better learning of task-specific knowledge.
Main Methods
GraphAdapter의 Main methods는 전체 Graph의 Sub-graph로 취급하는 Textual-subgraph와 Visual-subgraph의 Node와 Edge를 구성하는 요소가 무엇인지 이해하고, 두 subgraph가 학습에서 어떻게 Optimization 되는지 이해하는게 중요하다고 생각한다.
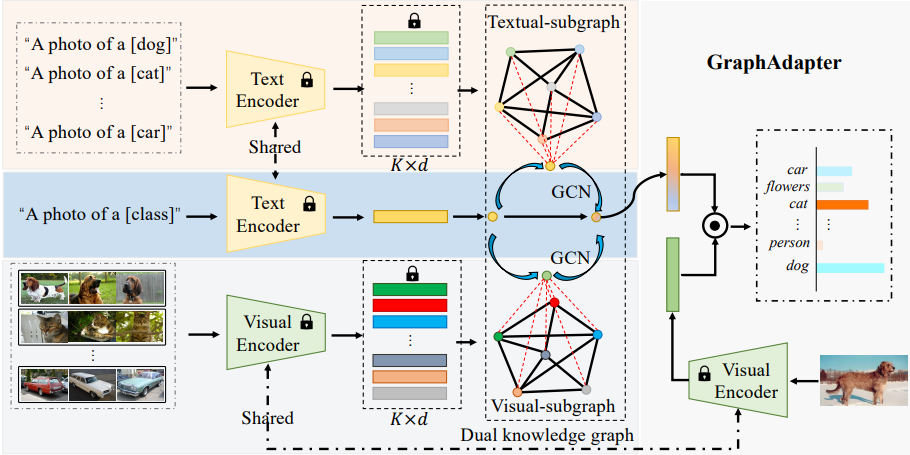
위 Figure는 논문의 Main figure이다. 이제 부터는 이 파이프라인의 Input부터 Result까지 하나씩 따라가 보겠다.
Input and Construction Graph
Pipeline 왼쪽의 Visual input과 Textual input에 Text Encoder와 Visual Encoder에 입력되는 데이터를 Input으로 볼 수 있다. 이 때 \(-\cdot -\)로 점선 처리 된 박스는 훈련을 위해 Refine된 Data로 각 Class 별 Prompt와 그와 mapping 되는 이미지 데이터이다.

Text Encoder와 Visual Encoder는 “A photo of a [CLS]” 와 [CLS]에 해당하는 사진을 각각 입력받고 feature를 embedding vector로 output한다.
이 때 Text Encoder와 Visual Encoder는 Pretrained model을 Fine-tune 없이 그대로 사용한다.(🔒)
embedding vector의 \(K \times d\) 에서 \(K\)는 데이터셋 내 Class의 개수를 의미하고 \(d\)는 hidden dimension을 의미한다.
그리고 각 embedding vector 자체를 node로 기준 삼아 아래의 식으로 edge weight를 계산하여 graph를 구성한다.
\[ \mathcal{E}_t = \{ e_t^{i,j} \}, \ e_t^{i,j} = \frac{c_t^i {c_t^j}^T}{|c_t^i| \cdot |c_t^j|},\ i,j \in [1, K] \]
위 식은 node set \(\mathcal{C}_t \in \mathbb{R}^{K\times d}\)의 두 원소인 node \(c^i_t,\ c^j_t\)의
즉 subgraph의 edge 가중치가 각각 Class의 embedding vector의 cosine similarity 라는 것인데, GraphAdapter의 저자들은 이를 이용해서 초반에 설명한 Class/semantic간 관계를 학습에 사용하고자 한다.
Visual subgraph의 Edge는 \(\mathcal{E}_v\) 로 표현한다.
정리하자면 GraphAdapter에서 다루는 Graph는
\[ \mathcal{G} = \{\mathcal{G}_v, \mathcal{G}_t\} = \{\{\mathcal{C}_v, \mathcal{E}_v\}, \{\mathcal{C}_t, \mathcal{E}_t\}\} \]
라고 할 수 있다.
Adapting with the dual knowledge graph
두 Subgraph로 Graph를 구성한 다음 저자들은 dual-modality를 효과적으로 응용하기 위해서 GCN (Graph Convolution Network)를 사용하여 Graph를 학습시킨다고 한다.

논문에서는 image sample(visual)과 prompt(textual)의 feature embedding이 미리 구성한 Graph의 structure knowledge에 warp 가능하다고 설명한다.
warp 라는 말이 좀 추상적이긴 한데… 내가 이해한 바로는 Encoder _(여기서는 CLIP Encoder를 사용한다.)_의 feature \(z\)를 sub-graphs의 node로 구성할 수 있는데, 이 과정에서 \(z\)를 query로 두고 GCN 연산을 통해서 해당 query에서 비롯된 \(\mathcal{C}_t, \mathcal{C}_v\)를 계산해낼 수 있다는 것이다.
저자들은 visual sub-graph와 textual sub-graph를 대상으로 하는 query를 \(z_t\) 로만 설정하고 \(z_t\)를 각 sub-graphs에 warp 했다고 말한다.
이렇게 하면 textual feature \(z_t\)는 2개의 modality의 특성을 고려한 node로 간주될 수 있으며, GCN 연산을 통해 dual-modality structure knowledge by interacting with two sub-graphs in the same graph space를 수행할 수 있다.
Optimization Process
이제 CLIP Text Encoder의 output인 \(z_t\)를 고려하여 원래 준비되어 있던 Subgraph들을 다음과 같이 확장(Extend)한다.
\[ \mathcal{C}_{tt}=[z_t, \mathcal{C}_{t}], \ \ \mathcal{C}_{vt}=[z_t, \mathcal{C}_{v}] \]
이어서 \(z_t\)와 각 Subgraphs의 Node들 \((\mathcal{C}_t, \mathcal{C}_v)\) 간의 Edge 표현은 아래와 같다.
\[ \begin{bmatrix} 1 & \text{sim}(z_t, \mathcal{C}_t) \\ \text{sim}(\mathcal{C}_t, z_t) & \mathcal{E}_t \end{bmatrix}, \ \begin{bmatrix} 1 & \text{sim}(z_t, \mathcal{C}_v) \\ \text{sim}(\mathcal{C}_v, z_t) & \mathcal{E}_v \end{bmatrix} \]
여기서 \(\text{sim}\)은 similarity를 의미하며 위에서 설명한 cosine similarity 수식이라고 생각하면 된다.
그 다음으로 \(g_{tt}\) \(g_{vt}\) 를 각각 \(\mathcal{C}_{tt}\), \(\mathcal{C}_{vt}\)에 대한 visual-text Graph Convolution Network라고 하자.
그리고 다음의 식으로 adapting texture feature \(\mathcal{C}^{*}\) 를 얻을 수 있다.
\[ \mathcal{C}^{*}_{tt} = g_{tt}(\mathcal{C}_{tt}, \hat{\mathcal{E}}_{tt}) = \sigma (\hat{\mathcal{C}}_{tt}\mathcal{C}_{tt} W_{tt}), \ \mathcal{C}^{*}_{vt} = g_{vt}(\mathcal{C}_{tt}, \hat{\mathcal{E}}_{vt}) = \sigma (\hat{\mathcal{C}}_{vt}\mathcal{C}_{vt} W_{vt}) \]\(W\): weight of each GCNs
\(\hat{\mathcal{E}}_{tt}\)와 \(\hat{\mathcal{E}}_{vt}\)는 각각 \(D^{-\frac{1}{2}}_{tt}\mathcal{E}_{tt}D^{-\frac{1}{2}}_{tt}\) 와 \(D^{-\frac{1}{2}}_{vt}\mathcal{E}_{vt}D^{-\frac{1}{2}}_{vt}\) 으로 표현된다.
\(D_tt\)와 \(D_vt\) 는 다음과 같다.
\[ D_{tt} = \text{diag}(\sum^{K}_{p=1}(\mathcal{E}_{tt} + I)_p), \ D_{tt} = \text{diag}(\sum^{K}_{p=1}(\mathcal{E}_{vt} + I)_p) \]
여기서 \(ABA\) 구조로 행렬곱을 구성한 것은

간단히 말하자면 GCN에서 사용되는 Edge 정규화 기법이라고 이해하면 된다. (CNN에서 Batch norm을 하는 이유와 동일하다.)
위 과정을 거쳐서 기술적으로 새로운 adapted/refined textual feature는 \(z_{tt},\ z_{vt}\)라고 하고 아래의 과정으로 구한다.
\[ z_{tt} = \mathcal{C}^{*}_{tt}[0,:], \ z_{vt} = \mathcal{C}^{*}_{vt}[0,:], \]
최종적으로 두 \(z\)는 CLIP Text Encoder의 output에서 출발하여, 목적 downstream task의 Class feature를 Dual-modality (Visual/Textual) 성질로 갖게 되는 fused \(z\)로 계산 되는데 그 계산은 아래와 같다.
\[ z^{\prime}_{t} = \beta * z_{tt} + (1-\beta)*z_{vt}, \ z^{*}_t = \alpha z_{t} + (1-\alpha)z^{\prime}_{t} \]
GraphAdapter에서는 GCN에 해당하는 오로지 \(g_{tt}\), \(g_{vt}\) 만 trainable 하고, 이 네트워크는 실제 label과의 cosine similarity로 예측된 predicted label의 cross entropy function으로 학습된다.

Experiments
이제 실험 결과들을 살펴보자. 다른 Foundation Model들과 다를 바 없이 여러 데이터셋 상에서 \(0,\ 1,\ 2,\ 4,\ 8,\ 16-shots\) 훈련을 실행 한 뒤 측정했다. 결과는 아래와 같다.

다음은 generalization capability를 측정한 결과이고 ImageNet을 대상으로 실험하였다.

아래는 ablation study중 backbone에 대한 study인데 CLIP Encoder의 Backbone을 다양하게 실험해봤을때의 결과치이다. ViT-B/16 (가장 큰 모델)일 때 성능이 좋은걸 보아하니 역시 이런 모델은 Backbone의 영향을 많이 받는다는 것을 알 수 있다.

Conclusion
과거에 GNN, GCN을 살짝 찍먹했었을때가 있었는데 이걸 VLM 아이디어에 적용하여 준수한 성능을 낼 수 있었다는 것이 흥미로웠다. 아직 문제 정의는 좀 찜찜하지만 Class embedding을 Node로 취급하고 Embedding간의 Cosine similarity를 Edge weight로 설정하는 것은 보기엔 쉬워보이지만 처음부터 생각하기에는 꽤 참신한 아이디어라고 생각했다.
어려운 테크닉은 없었지만 다른 분야와의 mash-up이 잘 이뤄진 case라서 논문 주제의 방향성에 대해서 생각해볼 수 있는 계기가 되었다. 대체적으로 요즘엔 간단한 아이디어로 참신하게 풀어낸 연구가 학계에서 잘 받아들여지는것 같다.