Using Language To Extend to Unseen Domains
Lisa & Aditi et. al (UC Berkeley, Carnegie Mellon Univ.) 이 ICLR`23 (notable top 25%)에 게재한 Using Language To Extend to Unseen Domains 를 읽고 작성한 논문 리뷰입니다.
<CODE> <PAPER> <Blog> <OpenReview>
Abstract
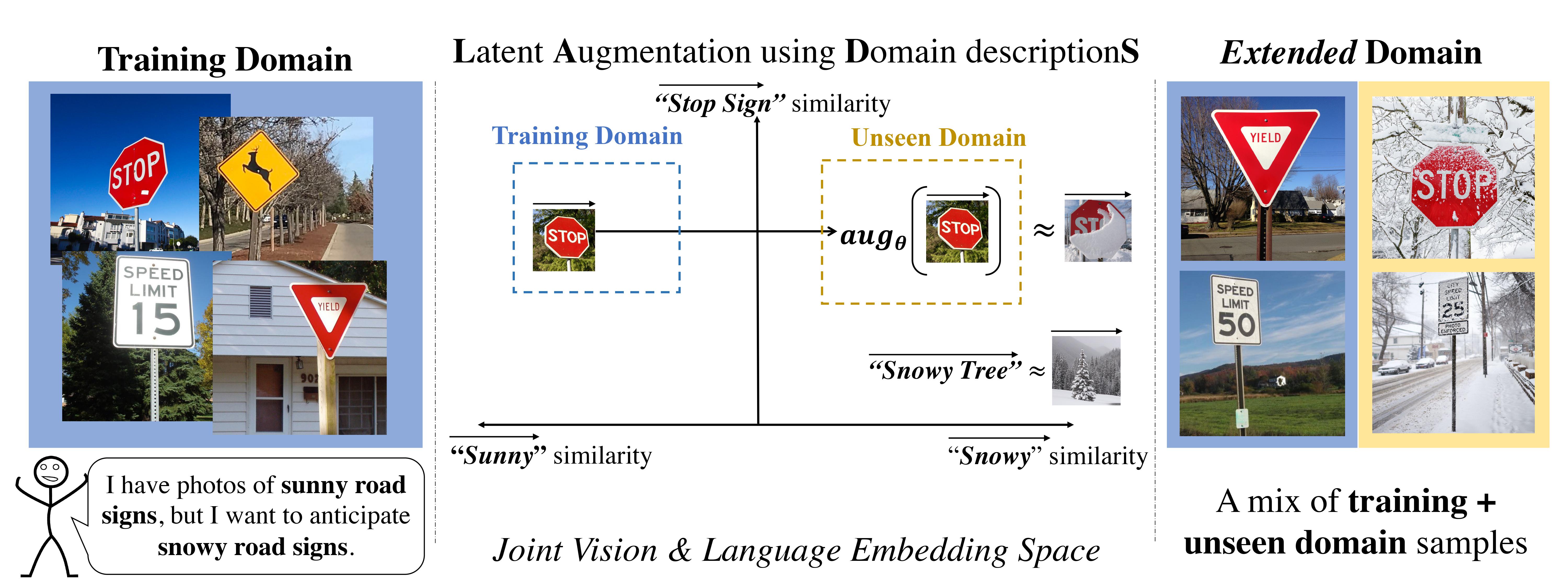
이 논문은 훈련중 보지 않은 도메인(Unseen Domain)에 대하여 Classification을 수행하는 Domain Generalization & Adaptation과 관련된 논문입니다. 논문에서는 Unseen Domain의 Sample을 보지 않는 대신 자연어로 언어화 된 Domain description을 활용해서 Augmentation Network를 훈련시키는 것을 목적으로 합니다.
이 Network는 이미지의 Class 관련 정보를 유지하면서 Source domain에서 Unseen domain으로 Multimodal Image Embedding을 변환하는데 사용됩니다. 그런 다음 원본 Image에 대한 Embedding과 Augmented Image에 대한 Embedding을 함께 사용해서 Classifier를 훈련시킵니다.
필자는 이 논문의 Task는 Domain adaptation과 더 가깝다고 생각합니다. 그 이유는 Domain Generalization은 훈련 절차중에서 Unseen Domain에 대한 ’정보’를 절대 포함하지 않는 상황이어야 하기 때문입니다. 보이지 않는 도메인에 대한 Text description을 전달하기 때문에 Domain Adaptation에 더 가깝다고 생각합니다. 하지만 Unseen Domain Image Samples를 사용하지 않는다는 것에 Novelty가 있는 것은 분명합니다.
저자들은 Extended domain(Training domain+Unseen domain)인 상황에서 Standard fine-tuninng and ensemble approach들 보다 이 논문의 방식인 LADS가 더 뛰어나다나는 것을 보여줍니다.
Main Idea
 👆Architechture Overview Animation
👆Architechture Overview Animation

Puffin과 Sparrow(참새)를 분류하는 것이 현재 문제라고 가정해봅시다. Training 데이터 \(D_{training}\)에는 두 Class의 사진이 포함되어 있지만 Classifier를 위 그림, 즉 \(D_{unseen}\)에 대한 정답도 잘 맞출 수 있도록 학습하고 싶습니다.
이를 위해 Training과 Unseen Domain에 대한 Text description인 \(t_{training}\)과 \(t_{unseen}\)을 각각 사용하고자 합니다. Augmentation 네트워크 \(f_{aug}\)는 도메인 정렬 손실(Loss of Domain alignment) \(L_{DA}\)와 클래스 일관성 손실(Loss of Class consistency) \(L_{CC}\)를 사용하여 이미지 임베딩을 \(D_{training}\)에서 \(D_{unseen}\)으로 변환 할 수 있도록 Training됩니다.
- \(L_{DA}\)가 낮으면 Augmentation된 임베딩이 기존 도메인이 아닌 새로운 도메인에 있지만 해당 클래스에서 벗어났을 수 있습니다.
- \(L_{CC}\)가 낮으면 Augmentation된 임베딩은 클래스 정보를 유지하지만 원하는 도메인 변경을 반영하지 못할 수 있습니다.
\(f_{aug}\)는 \(L_{DA}\)과 \(L_{CC}\) 값이 낮도록 일종의 Space로 모든 이미지 임베딩을 Augmentation하는 것을 목표로 하며, 그 결과 \(f_{aug}(I(x))\)는 클래스 정보는 Puffin이고 도메인은 Painting인 이미지와 유사한 이미지 임베딩을 갖게 됩니다.
오른쪽의 hallucinated 이미지 임베딩은 각 Loss 함수의 효과를 그림으로 표현한 것이며 실제로 LADS에 의해 생성된 것이 아닙니다.
vs CLIP
Fine-tuning under Distribution Shift
Fine-tuning under Distribution Shift는 pretrained model을 바탕으로 새로운 Task, 새로운 Dataset에 올바르게 맞춤화하는것(tailor)을 의미합니다. Kumar et al. (2022)는 Tailor 하고자 하는 Pretrained model backbone에 linear layer를 추가로 달아 Linear probing을 한 다음 model의 backbone을 finetuning 하는 것이 더 좋다고 설명했습니다. 또한 Wortsman et al. 2021은 CLIP과 같은 Zero-shot 인코더에 대해서 Zero-shot Encoder weights를 가지고 Image encoder를 finetuning하여 서로를 Ensemble하는 방법에 대해 제안했습니다. 본 논문은 이러한 아이디어의 대안(Complementary)이 되는 방법론을 소개하며 OOD performance를 증가시킬 수 있다고 말합니다.
Semantic Augmentation with CLIP
CLIP의 등장과 함께 여러 Paper들이 Language를 사용하여 CLIP과 Generative model을 조합하여 이미지를 변환(Semantic Augmentation with CLIP)하는 방법을 사용했습니다. 사용된 방법은 다음과 같습니다.
원본 이미지
\(\rightarrow\) CLIP 이미지 Embedding
\(\rightarrow\) CLIP 이미지 Embedding과 CLIP 텍스트 Embedding을 활용하여 새로운 이미지 Embedding으로 변환
\(\rightarrow\) 해당 Embedding을 사용하여 변경된 이미지를 생성
지금까지의 CLIP based works들은 이러한 Embedding Augmentation 방법을 dataset의 context bias 또는 domain adaptation에 활용된 적이 없었습니다. 그나마 몇 있던 이전 논문에서는 pixel level에서 이미지를 생성하는데 도움을 주고자 augmentation을 연구하는데 그치고 보통은 생성 이미지의 Quality에 한계점이 존재했습니다. 본 논문에서는 CLIP으로부터 Knowledge distillation을 효율적으로 하기 위해 Image Embedding을 directly하게 manipulate합니다.
Benchmarks
논문에서 평가 대상이 되는 Benchmark는 다음과 같습니다. 1. CLIP General Zero-Shot \([ZS(G)]\) - Text likes; {class} 2. CLIP Adaptive Zero-Shot \([ZS(A)]\) - Text likes; {domain} of {class} 3. CLIP Linear Probing \([CLIP-LP]\) and CLIP Linear Probing with Zero-Shot init.\([CLIP-LP(ZS)]\) 4. Ensembled CLIP Linear Probing \([WiSE -LP]\) 5. VQGAN trained with CLIP \([VQGAN+CLIP]\)
여기서 짚고 넘어가야 하는 Benchmark는 CLIP LP와 CLIP LP(ZS)입니다. CLIP LP(ZS)는 Wortsman et al. 2021에서 발표된 기법을 사용한 것으로, 각 Class를 지칭하는 Text를 CLIP Text Encoder에 통과시켜 나오는 Class Text Embedding을 Linear layer의 weights로 초기화 하는 것을 의미합니다.
따라서 weight의 dimension은 CLIP Text Encoder outputs와 같습니다. 본 논문에서는 CLIP LP(ZS)외에 CLIP LP를 추가로 평가대상으로 사용하는데, 이는 Text embedding이 아니라 각 클래스별 Image중에서 가장 Accuracy가 높은 Top Image embedding으로 weights를 초기화합니다.
Methods
Two Stage Approach
LADS는 2단계 접근 방식을 사용합니다.(two-stage approach) 1. 이미지의 픽셀 자체를 Transformation 하지 않고 이미지의 Embedding을 Augmentation을 함, 그와 동시에 Class label과 일치하는 특징을 유지하는 것을 목표로 함 2. 원본 이미지 Embedding과 Augmented된 Embedding을 모두 포함하는 Training 세트에 대해서 Linear Probing을 수행함.
 첫 번째 단계(Augmentation network 훈련)의 Overview
첫 번째 단계(Augmentation network 훈련)의 Overview
Text Description
Text description은 CLIP의 Text Encoder를 통과하여 Text Embedding이 되고 이는 Augmentatin network에 사용됩니다.
Input Text description은 \(t_{training} \centerdot t_{y}\) 으로 표현됩니다.
예를 들어서 \(t_{training}=\)a photo of a 라면 \(t_{unseen}=\)a painting of a입니다. 이때 \(t_{y}=\)Puffin이면 \(t_{training} \centerdot t_{y}=\)a photo of a Puffin입니다.
Objectives
Augmentation network를 학습하려는 목적은 \(t_{training}\) 과 \(t_{unseen}\)을 이용해서 이미지 Embedding을 \(D_{training}\) 도메인에서 \(D^k_{unseen}\)으로 Augmentation 하는것입니다. 그와 동시에 Transformed Embedding은 Class label에 대한 정보도 잃지 않아야 하기 때문에 논문에서는 2가지 Loss를 제시했습니다. > 1. Domain Alignment \(L_{DA}\) 2. Class Consistency \(L_{CC}\)
Domain Alignment \(L_{DA}\)
\[ \mathcal{L}_{\mathrm{DA}}\left(f_{\text{aug}}^k\right)=\sum_{i=1}^n 1-\left(\frac{f_{\text{aug}}^k\left(I_\theta\left(\mathbf{x}_{\mathbf{i}}\right)\right)-I_\theta\left(\mathbf{x}_{\mathbf{i}}\right)}{\left\|f_{\text{aug}}^k\left(I_\theta\left(\mathbf{x}_{\mathbf{i}}\right)\right)-I_\theta\left(\mathbf{x}_{\mathbf{i}}\right)\right\|} \cdot \frac{T_\theta\left(t_{\text{unseen }}^k, y_i\right)-T_\theta\left(t_{\text{traning }}, y_i\right)}{\left\|T_\theta\left(t_{\text{unseen }}^k, y_i\right)-T_\theta\left(t_{\text{training }}, y_i\right)\right\|}\right). \] CLIP은 Image embedding 의 space인 \(\mathcal{I}\)가 Text embedding의 space인 \(\mathcal{T}\)와 일치하도록 학습되었지만 \(\mathcal{I}\)와 \(\mathcal{T}\)가 반드시 어떤 모습으로 Mapping 되어야 하는지는 명확하지 않습니다.
게다가 (Patashnik et al., 2021; Gal et al., 2021)의 연구들에 따르면 \(D_{\text{training}}\) 에서 \(D_{\text{unseen}}^k\)로의 이동(Shift)과 맥락상 일치하는 Global Direction이라는 존재를 가정할 수 있습니다. 이것은 Image Embedding Space와 Text Embedding Space 두 공간에서 cross share 됩니다.
Global Direction은 Target domain의 Embedding과 Source domain의 Embedding의 Nomarlized diference로 정의됩니다.
Class Consistency \(L_{CC}\)
\[ \mathcal{L}_{\mathrm{CC}}(f_{\text{aug}}^k)=\sum_{i=1}^n \text{ Cross-entropy }(\operatorname{Softmax}\lbrack f_{\text{aug}}^k(I_{\theta}(\mathbf{x}_{\mathbf{i}})) \cdot T_{\theta}(y_i) \rbrack, y_i) \]
Domain Alignment loss는 오로지 Domain간의 차이안에서 Embedding을 Augmentation 하는 것에만 효과를 줍니다. 만약에 Domain shift에 오로지 하나의 Global shared direction만이 있다고 가정하면 \(L_{DA}\)만으로도 충분하겠지만 실제로는 \(L_{DA}\) 하나만 사용한다면 Class relevant information이 소멸할 가능성이 있고 그 결과 서로 다른 이미지의 Augmented Embedding간의 diversity가 부족하게 될겁니다.
따라서 논문에서는 Class Consistency loss를 추가하였고 이는 Augmented Embedding이 Class information을 보존하도록 하는 역할을 합니다.
함수는 실제 Class name text와 Augmentation network가 생성한 Image Embedding을 CLIP Zero-shot 방식으로 이미지를 정확하게 분류하는지를 측정합니다.
Final Objectives
\[ L_{\text{LADS}}({f^k_\text{aug}}) = \alpha{L_{\text{DA}}(f^k_\text{aug})} + (1-\alpha)L_{CC}(f^k_{aug}) \]
최종 Loss function의 수식은 위 수식과 같으며 \(\alpha\)는 hyperparameter로 Domain Alignment와 Class Consistency의 Trade-off를 조절하는 역할을 합니다.
Stage 2: Fine-tuning
\(f_{\text{aug}}^k\)가 훈련된 다음에 \(I_{\theta}(\mathbf{x}_i)\)와 \(f^{k}_{\text{aug}}(I_{\theta}(\mathbf{x}_i))\)를 함께 사용해서 Linear probing합니다. Inference는 별다른 과정없이 곧바로 하게 됩니다. test-image의 CLIP image embedding을 Linear probing에 사용합니다.
Addressing Dataset Bias
Exteded Domain을 처리하는 것 외에도, LADS는 Dataset에 가짜 상관관계(spurious correlation)가 있는 Dataset Bias 설정에도 사용할 수 있습니다.
예를 들어, 물새(Waterbirds)에서 육지새와 물새를 분류하고자 하는데, 이 때 가짜 상관관계가 배경(Background)이 됩니다. (training에서 육지새는 숲 배경에 나타나고 물새는 물 배경에 나타남).
분류기가 이 상관관계를 사용하여 예측하는 것을 방지(Overfitting을 방지)하기 위해 LADS를 사용하여 “물 위의 육지새”와 “육지 위의 물새”를 나타내는 증강을 생성할 수 있습니다.
이를 위해 CLIP을 사용하여 각 이미지의 배경에 레이블을 지정한 다음 예제별로 \(t_{\text{training}}\)과 \(t_{\text{unseen}}\)를 결정합니다.
도메인 정보 \(t_{\text{land}}=\) "a {} in the forest", \(t_{\text{water}}=\) "a {} on the water" 가 주어지면 Zero-shot CLIP을 사용하여 주어진 이미지가 육지에 있는지 물 위에 있는지 판단할 수 있습니다.
이미지가 육지에 있는 것으로 예측되는 경우, 해당 특정 예에 대한 \(f_{\text{aug}}\) , \(L_{DA}\)를 training할 때 \(t_{\text{training}}= t_{\text{land}}\), \(t_{\text{unseen}} = t_{\text{water}}\)을 사용하며 그 반대의 경우도 마찬가지입니다. Class consistency loss와 모델 파이프라인의 다른 부분은 변경되지 않습니다.
Vision 및 Language 모델을 사용하여 Domain label을 지정하기 때문에 Bias에 대한 이미지별 레이블이 필요하지 않고 Bias이 무엇인지에 대한 가설만 있으면 됩니다.
Implementation Details
\(f_{aug}\) : 2-layer MLP (output dim:\(768\) hidden dim:\(384\))
\(\text{CLIP}\) : ViT-L backbone, resize all images to \(224\times224\)
\(\text{Resource}\) : \(\text{RTX} 2080 \text{Ti} \times 10\)
Results

위 결과는 여러 데이터셋에서 Extended domain을 가정한 상황에서 LADS가 다른 Benchmarks 보다 우위에 있다는 것을 설명합니다. \(x\)축은 \(D_{training}\)의 비중을 의미합니다.(오른쪽으로 갈 수록 Extended domain에서 Training domain의 비율이 증가함) \(y\)축은 Classification 성능을 의미합니다.


 Training image embedding을 augmentation한 결과를 NN(Nearest-Neighbor)해본 결과 서로 다른 도메인이더라도 Specific class가 일치함을 보임
Training image embedding을 augmentation한 결과를 NN(Nearest-Neighbor)해본 결과 서로 다른 도메인이더라도 Specific class가 일치함을 보임
 각 Loss 함수 Ablation Experiment
각 Loss 함수 Ablation Experiment